
Cómo ver la TV desde el ordenador Ver la televisión en el ordenador es una cosa muy sencilla, gracias tanto a la oferta que existe en…
No te pierdas nuestras comparativas, artículos prácticos, trucos y consultas. Toda la mejor información está en PC Actual by Malavida.
Cómo ver la TV desde el ordenador Ver la televisión en el ordenador es una cosa muy sencilla, gracias tanto a la oferta que existe en…

Kodi es un potente y versátil centro multimedia puede reproducir cualquier contenido que tengas alojado en tu ordenador. Música,…

Los amantes de los videojuegos contamos con una variedad y cantidad de títulos a los que jugar cada vez mayor. Y jugar en PC suele ser una de…

Los atajos de teclado para Excel en macOS te permiten ejecutar acciones básicas y avanzadas de la aplicación con…

Los atajos de teclado en Word te van a ayudar a trabajar más rápido. En esencia, son combinaciones de teclas que te permiten…

Avast, uno de los antivirus más populares y confiables, ofrece una amplia protección contra las amenazas cibernéticas. Sin…

Aunque no lo parezca, los ficheros APK no solo funcionan en Android. Este tipo de archivos también pueden ser utilizados en ordenadores con…

En esta guía te lo contamos todo acerca de BlueStacks Portable. Te vamos a explicar qué son exactamente este tipo de aplicaciones…

En esta guía te voy a explicar cómo pasar archivos de BlueStacks a Windows. Te muestro el procedimiento más sencillo…
En esta guía te vamos a explicar cómo pasar archivos de Windows a BlueStacks. O, dicho de otro modo, te mostramos qué pasos…

GTA SA o GTA San Andreas apenas necesita presentaciones. Este título de Rockstar es la secuela de GTA Vice City y la precuela de Grand Theft…

En esta guía te vamos a explicar algunas soluciones para quitar la contraseña de WinRAR, es decir, un archivo comprimido con este…

La saga Grand Theft Auto no necesita presentaciones. Revolucionó los juegos de mundo abierto y tiene millones de jugadores en todo el mundo.…

En esta guía te lo contamos todo acerca de BlueStacks. Primero, vamos a hablar sobre qué es exactamente esta…

Instalar juegos en PC es una experiencia menos dolorosa gracias a las tiendas de juegos. Si bien hay varias de ellas, todas tienen en común…

Aunque la cantidad de marcas que apuestan por el mercado de las tablets es menor que las que lo hacen por el del smartphone, cada año se…

Aunque el auge de los portátiles se ha hecho más que patente, los fabricantes aún siguen apostando por equipos más…

En pleno 2024, el mercado de los smartphones se ha diversificado como nunca. El comprador cuenta con una larga lista de marcas que ofrecen modelos en…

El mercado de portátiles de 2024 está destacando por el lanzamiento de algunos modelos muy interesantes. En los siguientes apartados…

Hay mucho software para Windows pero, ¿cuáles son los programas realmente imprescindibles, esos sin los que no podemos vivir? La…

En esta guía te vamos a explicar cómo instalar add-ons en Kodi para PC. Primero, te explicamos qué son exactamente estos…

En esta guía te vamos a explicar qué es un archivo PSD, cómo abrir uno de ellos de forma muy sencilla sin tener…

Una de las tres aplicaciones principales de Office, o Microsoft 365, es PowerPoint. A pesar de ser el programa de presentaciones más…

En esta publicación te presentamos las mejores alternativas a Canva. Reconocemos que nos encanta esta aplicación, pero puede que para…

En este artículo recopilamos las mejores alternativas a WeTransfer. Esta plataforma está especializada en el envío de…

En esta guía te contamos cuáles son todos los métodos que tienes a tu disposición para compartir pantalla en Discord…

En esta guía te vamos a explicar cuáles son los métodos más efectivos para hacer que Discord no se inicie…
¿Estás buscando las mejores alternativas gratis a Photoshop? En ese caso, las propuestas que te ofrecemos aquí te van a…

¿Te toca renovar la suscripción a Microsoft 365? ¿Estás pensando en comprar una licencia de Office 2021, pero no lo…

Puede que hace algunos años Word no tuviera rival. No obstante, en la actualidad es muy fácil encontrar buenas alternativas a…

En esta guía te vamos a explicar todo lo que necesitas saber acerca de los archivos RAR en Windows. Te mostramos qué son y para…

En esta guía te lo cuento todo acerca de WinRAR, una de las herramientas de compresión y descompresión más populares…

Los archivos ZIP son muy útiles a la hora de enviar archivos y, al mismo tiempo, reducir su tamaño. Incluso ofrecen la posibilidad…

Hasta ahora, Firefox era uno de los navegadores que tenía un menor catálogo de extensiones por no estar basado en Chromium. Sin…

En esta guía te lo contamos todo acerca de Microsoft 365 Copilot. Te mostramos, entre otras cosas, qué es exactamente este…

TeamViewer es una herramienta para la conexión remota entre ordenadores y otros dispositivos. Permite a los usuarios acceder y controlar de…

Vamos a explicarte cuáles son los trucos más interesantes para Windows 11, la última versión del sistema operativo de Microsoft. Nuestra intención es…

Hay dos palabras que a todos nos vienen a la mente cuando pensamos en programas ofimáticos: Microsoft Office. Cuesta mucho imaginarse un marco…

Windows 11 fue publicado el 5 de octubre de 2021 de manera oficial. Se trata de la última actualización lanzada por Microsoft,…

El mando es un instrumento esencial para disfrutar al máximo de los videojuegos. Con el paso de las generaciones, los gamepads han ido…

Las cámaras web continúan siendo muy utilizadas hoy en día, en gran medida gracias al teletrabajo, pero también debido a…

Es posible que, si estás buscando la manera de mejorar la cobertura de tu conexión a Internet, te hayas topado con la palabra PLC. En…

Los discos duros son uno de los componentes más importantes y a la vez que más frágiles de nuestro ordenador. Su misión…

Elegir unos nuevos altavoces no es una tarea sencilla. Si se quiere acertar en la compra, es imprescindible conocer bien qué…

Sin importar si lo usas para trabajar, jugar o consumir multimedia, el monitor de tu ordenador es una pieza clave a la hora de disfrutar de una…

En el mundo de la telefonía móvil los usuarios se enfrentan a un claro duopolio a la hora de elegir sistema operativo. Pueden…

El mundo de las videoconsolas, y el de los videojuegos en general, está en constante evolución. Los aficionados llevan décadas…

Es el componente más básico de la mayoría de los dispositivos electrónicos. Nos referimos a la placa base. Si en…

La electrónica de consumo nos ha facilitado la vida en muchos aspectos. También para los amantes de la lectura. Los libros…

En la historia reciente existen dos términos que tienen una gran importancia en el argot de Internet: router y módem. Ambos hacen…

La tarjeta gráfica es un componente fundamental en cualquier ordenador. Sin importar si se trata de una GPU integrada o dedicada, es…

A lo largo de los años se han utilizado diversos formatos para almacenar todo tipo de datos. Los soportes digitales revolucionaron la…

Encontrar una impresora que se adecúe a cada circunstancia es una tarea difícil. Por eso, hemos preparado esta guía de compra…

Un ordenador, ya sea de sobremesa o portátil, cuenta con una gran cantidad de componentes. Aunque todos son de vital importancia, el que hoy…

La tecnología, la electrónica de consumo, los videojuegos o el desarrollo de software son campos que cuentan con millones de adeptos en…

El televisor sigue siendo uno de los electrodomésticos más básicos de cualquier vivienda. En detrimento de la televisión…

Si te hallas inmerso en la búsqueda de una buena cámara de fotos y no sabes por dónde empezar, te recomendamos que sigas leyendo…

La irrupción del almacenamiento en la nube ha hecho que muchos usuarios hayan dejado de preocuparse por el tamaño y las…

Que WinRAR es una aplicación para comprimir ficheros lo sabe casi todo el mundo. Ahora bien, lo que no es tan conocido es que cuenta con una…

WinRAR es una aplicación de descompresión. Sin embargo, también cuenta con infinidad de herramientas para hacer justo lo…

Una de las principales funciones de WinRAR es la de comprimir archivos. De esta manera, se pueden compartir o almacenar más…

La fibra óptica es el tipo de conexión a Internet más rápido que existe. Su excelente instantaneidad se debe a que es…

El protocolo de descarga Torrent te permite descargar todo tipo de ficheros de manera sencilla y rápida. Dos de los gestores de descargas…

Configurar uTorrent para descargar más rápido es muy sencillo. En realidad, tan solo deberás ajustar algunos valores, tal y como…

eMule precisa de una serie de configuraciones iniciales que te ayudarán a descargar más rápido. La primera de ellas tiene que…

El formato GIF (Graphics Interchange Format) es un formato de archivo gráfico creado en el año 1987 que se usa de forma común en…

Dentro del mundo de la informática y a la hora de hablar de sistemas operativos muy probablemente hayas oído hablar de las versiones de…
Puede que hayas oído hablar del registro de Windows. Es una parte del sistema a la que no sueles acceder normalmente, a no ser que quieras…

Dentro de un ordenador, ya sea de sobremesa o portátil podemos encontrar distintos tipos de memoria. Algunas son memorias permanentes (como la…

En alguna ocasión puede que al estar navegando por Internet, de repente, pasen cosas raras y tu banda ancha no esté dando de sí…

De unos años a esta parte casi todos los que ya tenemos una edad estamos contagiados de una especie de fiebre de lo retro, que nos invade como…
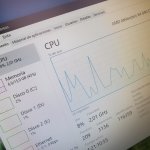
Si los ventiladores de tu ordenador se ponen a girar a velocidades altas, puede que sea una señal de que tu procesador está usando el 100% de los…
En ocasiones te habrás cruzado con algún reproductor de vídeo físico que soporta una gran cantidad de formatos... a…

En otros artículos hemos hablado ya de los muchos beneficios que puede comportar tener una Raspberry Pi: de tener una videoconsola retro, a un…
Volvemos a tratar el tema de la conversión de archivos de vídeo. En este caso vamos a volver ligeramente al pasado para hablar de aquellos tiempos en…

De unos años a esta parte puede que te hayas tenido que famliarizar (aunque ha sido un poco a la fuerza) con el asunto de los sistemas de 32 y…

Que el Blu-ray es un formato que vino para revolucionar la forma de consumir contenidos audiovisuales de los usuarios y que no terminó de lograrlo es…

El Blu-ray es un grandísimo formato, con unas capacidades para ver vídeo en alta definición que hacen las delicias de los más sibaritas de la imagen.…

Hace ya tiempo que las ventas de DVDs de series y películas no son lo que eran. Antes no quedaba más remedio que adquirir los soportes…

Hace unos años era habitual ver en los centros comerciales a cientos de personas comprando películas y series en DVD. Hoy en día…