Un ordenador, ya sea de sobremesa o portátil, cuenta con una gran cantidad de componentes. Aunque todos son de vital importancia, el que hoy nos ocupa, el procesador, es fundamental. En las siguientes líneas vamos a explicarte qué es exactamente un procesador, para qué sirve, cómo funciona y qué tipos de CPU existen. Si quieres saberlo todo acerca del cerebro de tu equipo, has llegado al lugar indicado. ¡Comenzamos!
Qué es un procesador
Empezamos esta guía estableciendo las bases. ¿Qué es un procesador? Es un circuito integrado que ejecuta las instrucciones que el usuario da mediante el sistema operativo o las aplicaciones. Contiene todos los elementos de lo que denominamos CPU. Estas siglas corresponden a Central Processing Unit, o lo que es lo mismo en español, unidad central de procesamiento. Por lo general, está situado dentro de un zócalo de la placa base. En equipos de sobremesa es fácilmente sustituible, siendo esta tarea mucho más complicada (y a veces imposible) en los portátiles.
Todos los equipos informáticos precisan de este componente para funcionar. Y con eso nos referimos a los ordenadores tradicionales, también considerados de escritorio, y a los dispositivos móviles. De igual manera, estos últimos también integran una unidad que se encarga interpretar las acciones del usuario.
Para conocer el origen de lo que hoy llamamos procesador, también conocido como microprocesador, debemos remontarnos a la década de los 50. En aquella época, diversas tecnologías relacionadas con los semiconductores fueron evolucionando hasta que en los años 70 se produjo el primer procesador. Como ha sucedido con tantos inventos modernos, los primeros pasos hacia la producción del procesador tuvieron, al principio, un fin militar.
El Intel 4004 fue un procesador de 4 bits que vio la luz en el año 1971. Se considera el primer microprocesador y fue diseñado para funcionar en una calculadora. En aquel momento contenía 2300 transistores y era capaz de realizar 60.000 operaciones por segundo. Su frecuencia de reloj era de 700 kHz. Tan solo un año después, Intel logró doblar la cantidad de bits con el Intel 8008, un procesador de 8 bits con mil transistores más que su antecesor. Se iniciaba en ese momento la carrera de las especificaciones.
En 1978 se produjo un hito histórico. Por primera vez se lanzaba al mercado un procesador de 16 bits. El Intel 8088 fue el inicio de la popular arquitectura x86. Otros fabricantes de renombre entraron en el mercado, siendo IBM uno de los más populares. Por ejemplo, en el 1982, lanzó un procesador x86 de 16 bits con 134.000 transistores y una frecuencia de reloj de hasta 25 MHz. Fue uno de los más utilizados en el mercado floreciente de la informática personal y doméstica.
En los siguientes años, los procesadores lograrían aumentar su velocidad, reducir su tamaño y ser más eficientes. Intel, IBM, Motorola y muchos otros fabricantes se enzarzaron en una batalla por lograr las mejores características en el ámbito del procesamiento de datos. Pero, ¿para qué sirve en realidad un procesador?
Para qué sirven los procesadores
 Para qué sirven los procesadores
Para qué sirven los procesadores
Una unidad central de procesamiento, o CPU, tiene como principal objetivo recibir, interpretar y ejecutar instrucciones. En esencia, todas las acciones que el usuario demanda a través del sistema operativo o de una aplicación llegan al procesador. Este las convierte en respuestas lógicas que afectan al funcionamiento del sistema o de un programa concreto.
Un ejemplo muy básico para entender el propósito del procesador es la introducción de caracteres mediante el teclado. Cada vez que se presiona una tecla la unidad de procesamiento recibe una señal que le permite identificar si se trata de una letra, un número o un símbolo. Dependiendo de otras variables, como la ventana activa o en qué estado se encuentre el equipo, la señal que reciba el procesador le llevará a ejecutar una acción u otra. Si el usuario se encuentra usando una aplicación para tomar notas, el procesador sabrá que debe mostrar el carácter en pantalla. Evidentemente, existen operaciones de alta complejidad, muy alejadas de la simplicidad de interpretar la pulsación de una tecla.
Además de las respuestas con respecto a software, el procesador también sirve para controlar al resto de componentes físicos del equipo. Esta capacidad de coordinar todo el hardware es imprescindible para que el usuario reciba respuesta a las instrucciones emitidas. Una CPU sería completamente inútil sin este poder de control. Siguiendo con el ejemplo anterior, además de entender qué tecla ha pulsado el usuario y dónde debe mostrarse el carácter correspondiente, el procesador debe ser capaz de mostrarlo en pantalla. Eso es posible gracias al control que ejerce sobre la salida de vídeo del ordenador.
En resumidas cuentas, un procesador sirve para interpretar las acciones del usuario y de dar respuesta a ellas de la manera más adecuada. Para lograrlo, es necesario realizar una serie de operaciones matemáticas. ¿Cómo funciona un procesador? Te lo descubrimos en el siguiente apartado.
Cómo funciona un procesador
Hay algunos conceptos que es necesario aclarar para entender a cabalidad el funcionamiento de un procesador.
Arquitectura de Von Neumann
 Arquitectura de Von Neumann
Arquitectura de Von Neumann
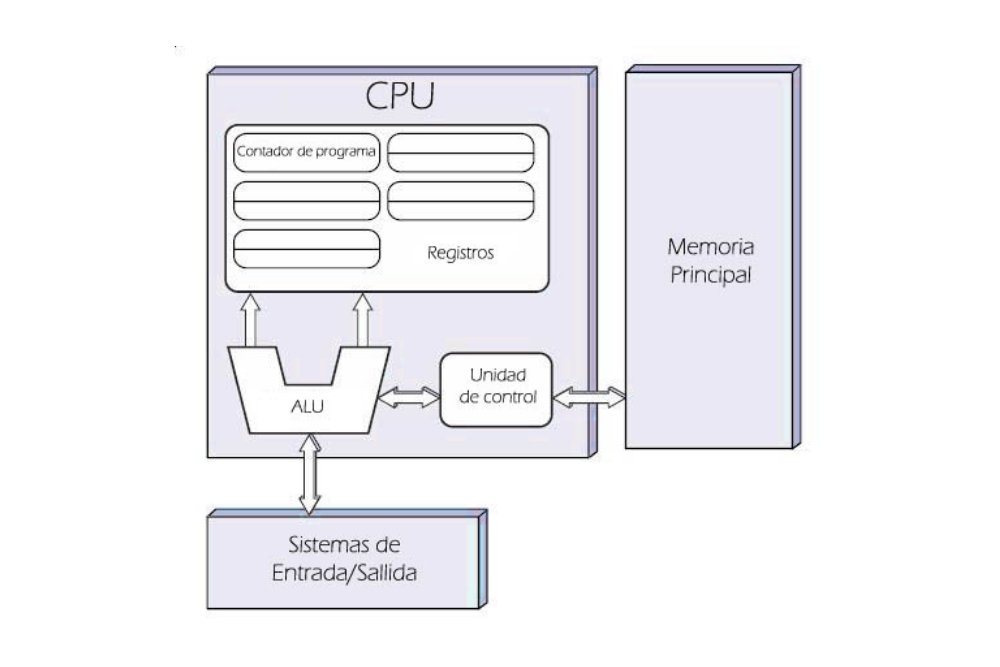
La arquitectura de Von Neumann es un esquema que siguen todos los equipos informáticos de la actualidad. Su origen se remonta al año 1945 y fue descrita por John von Neumann, un matemático y físico de origen húngaro. Dentro de este esquema hay cuatro componentes principales:
- La CPU. Es el componente principal encargado de procesar los datos. Interactúa con el resto de los componentes de la arquitectura para dar respuesta a las demandas del usuario.
- Sistemas de entrada y salida (E/S). Con este sistema, el procesador puede comunicarse con los periféricos, como el ratón, el teclado o la pantalla. La expresión “entrada y salida” hace referencia a las dos tipologías de periféricos existentes. En la primera se engloban todos aquellos periféricos que envían información al procesador, por ejemplo, el teclado. En la segunda, todos aquellos que la transmiten hacia al usuario, por ejemplo, el monitor.
- Memoria principal. En ella se almacenan las instrucciones que el procesador deberá interpretar y ejecutar.
- Buses. Son los cables por los que viajan los impulsos eléctricos y que se encargan de enlazar todos los componentes.
Conociendo la arquitectura de Von Neumann es mucho más sencillo saber cómo funciona exactamente un procesador. De hecho, es fundamental para ubicarlo dentro de todo el esquema de componentes que conforman un equipo informático.
Las instrucciones
Una vez hemos señalado la ubicación exacta del procesador y el lugar que ocupa respecto al resto de los dispositivos, es momento de hablar de las instrucciones. Ya apuntábamos en el apartado anterior que el procesador es el encargado de recibir y ejecutar instrucciones. Debemos recordarte que estas llegan en forma de impulso eléctrico.
Las instrucciones u órdenes que recibe un procesador se escriben en lenguaje binario. Este utiliza únicamente dos cifras numéricas: el cero (0) y el uno (1). Cada instrucción es una secuencia de unos y de ceros que le indica al procesador qué tipo de operación debe realizar, ya sean restas, sumas, multiplicaciones o divisiones. La CPU también es capaz de realizar operaciones lógicas basadas en verdadero o falso que permiten introducir variables y condicionantes.
Las instrucciones están previamente definidas. Es decir, existe una cantidad concreta que el procesador es capaz de entender. Estas se determinan dentro de cada plataforma en lo que se denomina conjunto de instrucciones. En los procesadores modernos existen distintos tipos. En el siguiente listado te mostramos algunos ejemplos:
- Transferencia de datos. Son aquellas que le indican a la CPU que debe mover datos de un origen a un destino.
- Aritméticas. Se usan para incrementar valores, sumar, multiplicar, dividir o cambiar de signo.
- Lógicas. Las instrucciones lógicas incluyen operaciones booleanas como Y, O, o NO (negación).
- Entrada y salida. Son aquellas que permiten leer la entrada de datos por parte de los distintos periféricos conectados. De igual manera, escriben información en los dispositivos de salida. La lectura y escritura se realiza en el puerto donde está conectado el dispositivo.
Además de estas, existen instrucciones de control, de bits o de comparación.
Elementos internos de la CPU
Hasta este punto hemos desvelado dos conceptos básicos de la computación: qué posición ocupa la CPU respecto al resto de los componentes y qué son exactamente las instrucciones. Teniendo claros ambos puntos, es el momento de hablar de lo que se encuentra dentro de la CPU, es decir, sus componentes internos. Una CPU está compuesta por diversos registros que le permiten funcionar correctamente.
- Unidad de control. Sus siglas son UC, por su nombre en inglés. La función principal que tiene es la de buscar instrucciones en la memoria principal, interpretarlas y ejecutarlas. Algunas de sus partes internas son el reloj, que sincroniza las operaciones, el contador de programa, que indica dónde se encuentra la siguiente instrucción en la memoria, y el registro de instrucciones, que alberga la instrucción actual. También componen la unidad de control el secuenciador y el decodificador de instrucciones. Este último se encarga de interpretarlas y ejecutarlas.
- Unidad aritmeticológica. Conocida por sus siglas en inglés ALU. Es la encargada de realizar las operaciones más básicas, como la suma y la resta, y las operaciones lógicas, con condiciones como SI, NO, Y, O. Está compuesta por el circuito operacional, los registros de entrada, el acumulador y el registro de estado.
- Unidad de coma flotante. Es un componente que no fue incluido en los procesadores más primigenios. Sin embargo, debido al aumento de la complejidad en las operaciones se ha hecho cada vez más necesario. Puede realizar cálculos trigonométricos y exponenciales.
- Memoria caché. Es una memoria interna que hace de enlace entre la memoria RAM y el procesador. Es mucho más rápida que la memoria RAM y eso permite acelerar el cálculo y ejecución de las órdenes.
- Buses. Por un lado, el bus frontal, que conecta la CPU con la placa base y esta, a su vez, con las tarjetas conectadas y el resto de las componentes del equipo. Por otro lado, el bus trasero, que comunica la memoria caché con el procesador. En la mayoría de los casos, este bus forma parte del propio procesador debido a que la memoria caché está integrada.
Tipos de CPU
Con las bases establecidas del funcionamiento de un procesador, es el momento de clasificarlos según la tipología. Hemos dividido este apartado en tres: por su arquitectura, por el fabricante y por la finalidad del procesador.
Según su arquitectura
Un procesador puede estar construido en diversas arquitecturas. Cada tipo de arquitectura delimita qué instrucciones están permitidas y cuáles no. De esta manera, a la hora de desarrollar programas, aplicativos o sistemas operativos, se debe tener en cuenta cuáles son las instrucciones que el procesador va a ser capaz de entender, interpretar y ejecutar. Asimiso, la arquitectura también influye en la disposición de los diferentes elementos físicos dentro de la unidad de procesamiento.
En la actualidad podemos destacar dos arquitecturas. En primer lugar, la x86. En esta se incluyen todos los procesadores que usan el conjunto de instrucciones del Intel 8086. En la actualidad, mantiene la compatibilidad con los procesadores de 16 bits de Intel. Sin embargo, otras marcas como AMD usan este juego de instrucciones para diseñar sus CPU. Aunque x86 engloba procesadores de 32 bits y de 64 bits, los últimos son comúnmente conocidos como x64.
En segundo lugar, la arquitectura ARM, que es de tipo RISC. Por lo tanto, dispone de un conjunto reducido de instrucciones que le permite funcionar con un número menor de transistores que los procesadores x86. Gracias a esta característica, los procesadores ARM son más pequeños, tienen menor consumo y su coste de fabricación es reducido. Estas virtudes les han permitido estar presentes en todo tipo de dispositivos portables y de tamaño reducido, como teléfonos móviles, teléfonos inteligentes, calculadoras o reproductores de contenido multimedia. Con todo, el rendimiento de los procesadores ARM ha mejorado notablemente en los últimos años y algunos fabricantes, como Apple o Microsoft, ya los usan en equipos de escritorio.
Según el fabricante
 AMD es uno de los principales fabricantes
AMD es uno de los principales fabricantes
Desde la aparición del primer microprocesador, han existido diversas marcas que han tratado de destacar en el campo del procesamiento de datos. De todas ellas, dos son las han logrado mantenerse en primera línea en los últimos años: Intel y AMD.
Intel se ha hecho fuerte gracias a su gama i3, i5, i7 e i9. Su última generación, la undécima, destaca por su gran potencia, incluso en la gama básica. Son procesadores perfectos para aquellos que deseen obtener el mayor rendimiento en la ejecución de videojuegos o tareas de edición de vídeo. Asimismo, son procesadores muy eficientes. Esto último es especialmente importante en dispositivos portátiles. Como contrapartida, el dominio del mercado por parte de Intel le ha permitido vender sus productos a un precio más elevado que el de la competencia.
AMD, por su parte, ha tomado relevancia en los últimos años gracias a su gama Ryzen. Disponen de una relación calidad precio inigualable, sobre todo por el rendimiento que ofrecen en sus versiones de gama media y gama alta. La compañía también ha logrado que sus procesadores sean altamente eficientes. Debido a esto, muchos fabricantes de portátiles empiezan a emplearlos en sus equipos.
Al menos de momento, ambos fabricantes usan la arquitectura x86-64 en sus procesadores. ¿Qué pasa con ARM? En general, esta arquitectura ha quedado relegada al mundo móvil. No obstante, la tendencia parece estar cambiando y algunas compañías del sector empiezan a apostar por ARM a la hora de construir equipos de sobremesa.
Según la finalidad de uso
Un procesador puede tener diferentes finalidades. Es cierto que todos sirven para lo mismo, la interpretación y ejecución de instrucciones. Sin embargo, además de las CPU que se emplean en los equipos de escritorio o portátiles, existen otros procesadores más específicos.
Aunque a lo largo de este artículo hemos hablado de unidades de procesamiento vinculadas a las siglas CPU, también podemos identificarlas como GPU. ¿Por qué? Las GPU, en inglés graphics processing unit, son unidades dedicadas al procesamiento de gráficos. Su objetivo es aliviar la carga de trabajo de la unidad principal, la CPU, cuando se trata de ejecutar videojuegos o tareas similares. No obstante, las GPU también pueden ayudar a la CPU en otras tareas no vinculadas a los gráficos. Este modelo se denomina GPGPU.
Además de las unidades de procesamiento gráfico, puedes encontrarte con procesadores diseñados para funcionar en servidores de datos. Una de las gamas más populares en este ámbito ha sido diseñada por Intel y es conocida como Intel Xeon. Aunque son consideradas CPU corrientes, sus características les permiten ofrecer un excelente rendimiento y una gran velocidad en las operaciones. El producto equivalente a los Intel Xeon propuesto por AMD son los EPYC, pensados para el análisis de datos, la computación en la nube y la virtualización.
Por último, hablamos de los procesadores diseñados para funcionar en dispositivos móviles. Estos suelen utilizar la arquitectura ARM, son de menor tamaño y cuentan con una gran eficiencia energética. En cualquier caso, sin importar la finalidad de uso, todos los ejemplos citados en este apartado son considerados microprocesadores.
Características de un procesador
Además de la tipología, en un procesador es posible identificar una serie de características. ¿Quieres conocerlas? Entonces, sigue leyendo.
Frecuencia de reloj
La frecuencia de reloj en un procesador indica la velocidad a la que los transistores abren y cierran el flujo de electricidad. Por lo tanto, está estrechamente ligada a la potencia de este. La unidad utilizada para realizar esta medición son los hercios. En la actualidad, lo más común es que se utilice el gigahercio (GHz). Sin embargo, los primeros procesadores tenían frecuencias de reloj expresadas en kilohercios. Las CPU más modernas permiten realizar una operación de aumento de hercios, conocida como overclock. Así es posible absorber tareas de mayor peso en momento puntuales.
Anchura del bus
La anchura del bus se relaciona con el tamaño de las instrucciones que es capaz de ejecutar el procesador. En la actualidad, la anchura más utilizada es de 64 bits, aunque todavía es posible encontrarse con equipos que admiten hasta 32 bits. En este caso, es necesario que otro componente, la memoria RAM, sea capaz de almacenar cadenas del mismo tamaño que las que admite el procesador.
Eficiencia energética
Es una de las características más importantes, sobre todo cuando hablamos de equipos móviles. Es un valor expresado en vatios (W) que determina la autonomía del dispositivo. No olvidemos que este punto también es vital en los equipos de sobremesa que están conectados a la red eléctrica de forma constante. Cuanto más eficiente sea el procesador, más lo será el equipo en su conjunto. De esta forma, menor será el impacto en el medio ambiente y en la factura de la luz. Si en la anchura del bus la memoria RAM tenía mucho peso, en este caso es importante que la fuente de alimentación esté acorde a la potencia de la CPU. No debes pasar por alto que los procesadores más potentes tienden a consumir más.
Número de núcleos y de hilos
Un núcleo, conocido también como core, es una unidad de procesamiento incluida dentro de la CPU. En la actualidad, existen CPU de hasta 64 núcleos. Cada uno de ellos cuenta con los mismos componentes y dotan a la unidad de procesamiento de mayor capacidad para ejecutar instrucciones de manera simultánea. Por su parte, cada núcleo puede tener varios hilos internos. Estos núcleos virtuales permiten al procesador encarar las tareas más pesadas sin que el rendimiento general del sistema se vea afectado.
Zócalo
El zócalo es el conector que enlaza el procesador con la placa base. Cada procesador cuenta con número determinado de pines y un diseño específico. Esta característica es muy importante si te planteas montar tu propio ordenador. El zócalo del procesador elegido y el de la placa base debe ser el mismo.
Memoria caché
La memoria caché del procesador es una especie de memoria RAM mucho más rápida. Sirve para aumentar el rendimiento y facilitar el acceso a las instrucciones. La memoria caché se divide en tres niveles:
- L1. Es la más rápida porque se encuentra más cerca de los núcleos. Pero, a su vez, es la que menor capacidad tiene.
- L2. En el segundo nivel nos encontramos con una memoria un poco más lenta, pero con mayor capacidad.
- L3. En ella se puede guardar un mayor número de datos. Aunque es la más lenta, sigue siendo más veloz que la memoria RAM.
Refrigeración
Finalmente, hablamos de la refrigeración. Existen tres tipologías diferenciadas:
- Refrigeración pasiva. Es aquella que se obtiene mediante el uso de disipadores. Estos usan el contacto con el aire externo para enfriar la CPU.
- Refrigeración activa. En este caso, se fuerza la creación de un flujo de aire que impacta contra los disipadores. Para generar la corriente de aire se utilizan ventiladores.
- Refrigeración líquida. Es muy similar al sistema que se emplea en los motores de combustión. El calor se recoge mediante un líquido que se enfría en un radiador. Después, el líquido regresa a la CPU.
La correcta refrigeración de un procesador evita que su temperatura se eleve considerablemente. Esto es fundamental para que evitar pérdidas de rendimiento. Con una buena refrigeración, un procesador será capaz de soportar una mayor carga de trabajo de forma continuada.
Mejores marcas de procesadores
 Una GPU de NVIDIA
Una GPU de NVIDIA
Después de este análisis por los diferentes componentes de un procesador y sus características, toca echar un vistazo a las principales marcas de procesadores de la actualidad.
Intel
Empezamos con uno de los fabricantes de chips más importantes del planeta. De hecho, al inicio de este artículo te hemos hablado del Intel 4004, el primer microprocesador de la historia. La compañía se fundó en el año 1968 y, como algunos de sus competidores directos, tiene su sede en Santa Clara, California. Intel inventó la arquitectura x86.
¿Cuál es el punto fuerte de Intel? Ha sido el fabricante de referencia durante muchos años. A diferencia de otras marcas, que externalizan la fabricación, se encarga del proceso de diseño y producción de sus procesadores. Es la responsable de algunos de los hitos más importantes de la computación contemporánea.
AMD
AMD es, junto con Intel, una de las marcas de procesadores más conocidas del mundo. Fue fundada en 1969 y tiene su sede en California. Además de CPU, también es fabricante de placas base, tarjetas gráficas y otros productos relacionados.
¿Cuál es el punto fuerte de AMD? La relación calidad precio que es capaz de ofrecer en sus productos. El rendimiento de sus procesadores es muy bueno, sin disparar innecesariamente el coste total para el usuario. Lo mismo sucede con sus GPU, que son capaces de encararse con las de NVIDIA sin ningún tipo de problema.
Qualcomm
Qualcomm es una compañía de Estados Unidos que tiene su sede en San Diego, en el estado de California. Su historia se remonta a 1985 y, en la actualidad, son conocidos por sus laureados procesadores Snapdragon. Estos están diseñados para ser utilizados en dispositivos móviles que precisan de alta eficiencia energética.
¿Cuál es el punto fuerte de Qualcomm? Sin duda, su familia de procesadores móviles Snapdragon. Sin perder de vista que son CPU pensadas para teléfonos inteligentes, sus especificaciones llaman poderosamente la atención. Sin ir más lejos, el Snapdragon 865 Plus 5G ofrece conexión 5G, 144 fps y una velocidad de hasta 3,1 GHz.
MediaTek
MediaTek es una empresa fundada en el año 1997 de origen taiwanés. Sus procesadores se utilizan principalmente en el ámbito de los dispositivos móviles. Con todo, también es habitual encontrar sus productos en dispositivos relacionados con el almacenamiento, la geolocalización mediante GPS o la reproducción de contenido multimedia.
¿Cuál es el punto fuerte de MediaTek? Claramente la innovación en algunos campos clave de la informática móvil. Por ejemplo, en el año 2014 anunció el primer chip que incluía conexión Bluetooth, ANT +, GPS, Wifi y radio FM. En 2021 avanzó a Qualcomm y se situó como el primer fabricante de procesadores móviles a escala mundial.
NVIDIA
NVIDIA es una compañía norteamericana establecida en Santa Clara, California. Se fundó en el año 1993. Trabaja principalmente con unidades de procesamiento gráfico (GPU) para ordenadores personales, estaciones de trabajo y dispositivos móviles. También cuenta con una línea de productos propios centrados en los videojuegos llamada SHIELD. En la actualidad está centrada, además del mundo del videojuego, en la fabricación de chips para entornos profesionales y científicos.
¿Cuál es el punto fuerte de NVIDIA? Es una de las empresas más fuertes en el ámbito del procesamiento gráfico. Además de que sus tarjetas gráficas ofrecen unos resultados excepcionales en cuanto rendimiento, la firma también ha hecho grandes avances en el campo del software. Por lo tanto, sus productos permiten, además, retransmitir vídeo de alta calidad en directo o hacer capturas de pantalla. Todo, gracias a una serie de herramientas desarrolladas por NVIDIA.
TSMC
TSMC es una compañía taiwanesa que está especializada en la fabricación de semiconductores. Se fundó en el año 1987. Desde el año 2011 tiene un acuerdo con Apple para fabricar los chips que la compañía norteamericana desarrolla. Uno de los últimos procesadores fabricados por TSMC para Apple es el Apple Silicon M1, el primer procesador ARM pensado para equipos de escritorio que ha diseñado la firma.
¿Cuál es el punto fuerte de TSMC? Aunque no tiene una marca propia, ha colaborado con infinidad de compañías en el desarrollo de microprocesadores, como AMD, Intel, NVIDIA o Broadcom. Estas corporaciones se valen de la infraestructura de TSMC y de su capacidad de producción de obleas de silicio para diseñar, producir y comercializar sus productos.