
Excelente aplicación de reconocimiento óptico de caracteres
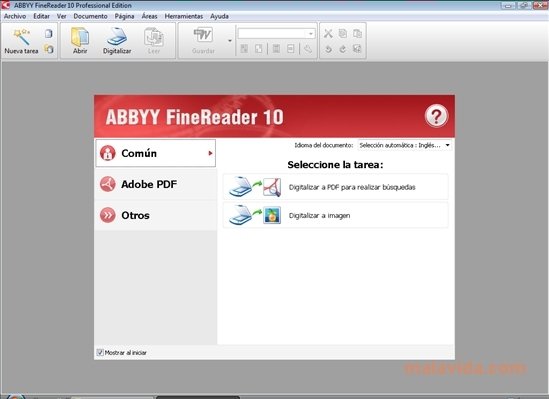
Para obtener copias digitales de tus documentos impresos en papel lo más habitual es emplear el dispositivo conocido como escáner, cuyo uso está bastante extendido entre los usuarios. Pero existen otros métodos como la toma de fotografías con una cámara digital. En cualquiera de estos casos resulta imposible modificar el contenido de los documentos convertidos al formato digital. Deberás descargar una aplicación como ABBYY FineReader para obtener ficheros editables.
Avanzado software de reconocimiento de caracteres
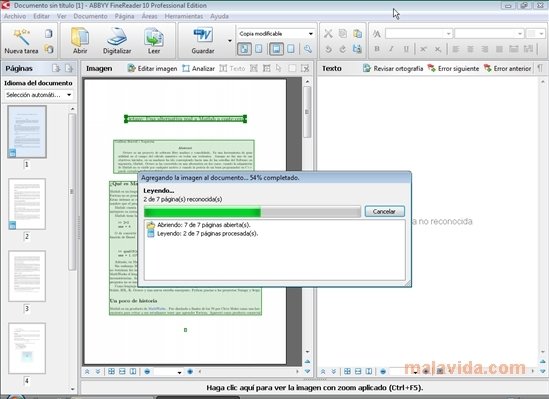
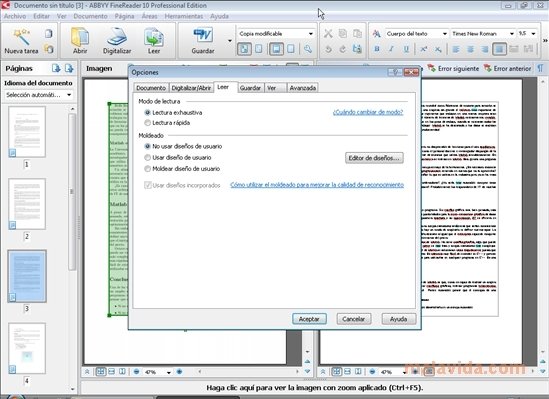
Si deseas modificar el texto o los datos contenidos en alguna de las copias que has generado en formato digital debes recurrir a un programa específico como este. Se trata de una solución OCR (Optical Character Recognition) avanzada, que permite realizar el reconocimiento óptico de caracteres de cualquier texto guardado en formato de imagen o PDF.
Algunas de las características son las siguientes:
- Reconocimiento óptico de texto en gran cantidad de idiomas: español, inglés, alemán, francés, portugués, finlandés, checo, húngaro, ..., y otros muchos más.
- Detección automática del idioma de los documentos.
- Válido para lenguajes artificiales (esperanto, ido, etc.), lenguajes de programación (BASIC, C++, Java, COBOL, ...) y fórmulas químicas simples.
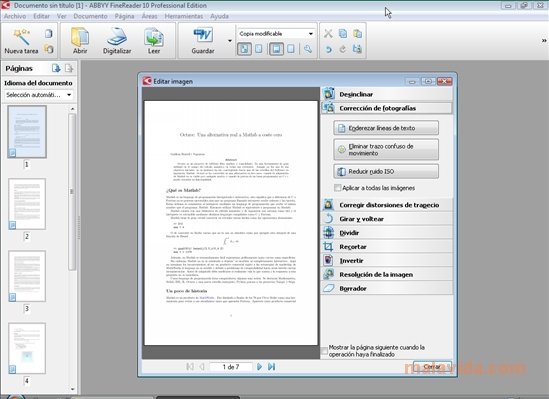
- Corrección automática de la distorsión y otros defectos en las imágenes.
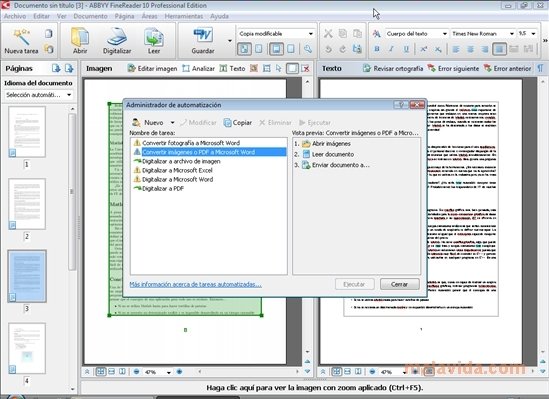
- Inclusión de accesos directos a las opciones más habituales: convertir una imagen o un PDF a Microsoft Word, digitalizar un archivo a PDF, Excel, Word, etc.
- Integración con el Explorador de archivos de Windows y con varios de los componentes de la suite ofimática de Microsoft (Word, Excel y Outlook).
- Empleo de la tecnología ADRT, específica de ABBYY.
Requisitos e información adicional:
- Se trata de una versión de prueba de 7 días con funciones limitadas.
 Elies Guzmán
Elies Guzmán
Licenciado en Historia y, más tarde, en Documentación, cuento con más de una década de experiencia probando y escribiendo sobre apps: reviews, guías, artículos, noticias, trucos… han sido innumerables, sobre todo en Android, sistema operativo...